

Introduction to the Linkerd Service Mesh



Michael Levan
March 21, 2023
Guest post by Michael Levan
When you deploy a pod, do you know if your application is running how you want it to? Is its traffic encrypted? Is your application performing as expected? Is it constantly timing out? Constantly retrying? These are all questions you have to ask yourself when running any application in production — containerized or not.
In this blog post, you'll learn how to answer these questions with a popular framework/platform that's becoming the de facto standard for network security and observability: a service mesh.
Why Use a Service Mesh?
At a high level, a service mesh allows you to understand what your containerized applications are doing at a network level.
Let's break that down a bit more.
Kubernetes conducts one primary task: to schedule containers. Yes, there's self-healing, auto-scaling, and several other features, but at the core of it, Kubernetes schedules pods (consisting of one or more containers) and places them on a node with the proper resources available to run them.
Kubernetes, out-of-the-box, is not meant to give you security, network visibility, or any other features. It gives you a platform that essentially says "choose your own adventure." Because Kubernetes is open source and because of its visibility in the engineering space, many vendors started building different plugins, frameworks, and third-party tools that you can use to not only give you the ability to choose your own adventure around how you want Kubernetes to look, but to give you the ability to customize a production-ready platform.
A service mesh is one of those third-party "tools" (or services, depending on how you categorize them) for network visibility and management.
There are three primary ways to think about what a service mesh does
1. Security
2. Reliability
3. Observability
Service mesh security
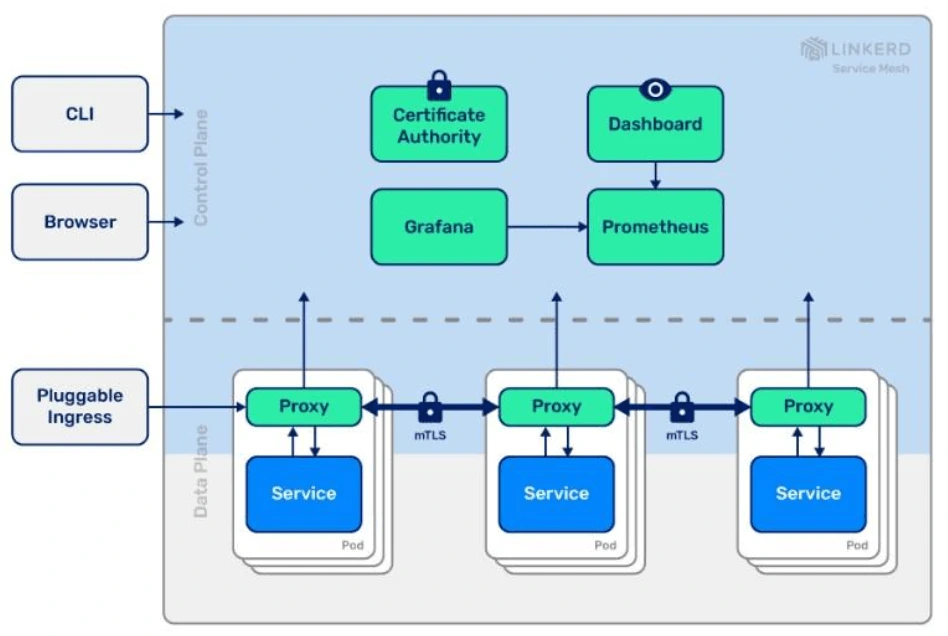
Security, crucial for any environment, is always a particularly major concern with pod networking. By default, all pods and services send fully unencrypted packets between other pods and services (typically referred to as east-west traffic). A service mesh solves this with mTLS. So how does it do that?
A service mesh container is injected into each pod with a containerized application, ensuring all traffic is encrypted within the pod network. This implementation is great because, typically, you'll see very flat networks. There are firewalls for traffic that goes outside and inside the network (egress and ingress), but once you're in the network, any pod can typically communicate directly with any other. With a service mesh, you're protected inside the pod network, while your firewalls protect traffic outside it. It's a security win-win at every layer!
Security, especially the mTLS/encryption piece, is a big reason why engineers choose a service mesh in the first place. There are many other benefits to a service mesh, but the packet/network encryption piece is often the thing that drives adoption in the first place.
Service mesh reliability
The second benefit is understanding whether your containerized applications are reliable. When it comes to reliability, you typically need to consider both a business cost/benefit analysis and the effect of additional reliability measures on the performance of the application. When a pod is deployed, the application running in it may or may not be working as expected. For example, constant retries may occur until it times out. This is definitely an engineering problem, but it’s also a business problem: if the application isn't running as expected, users cannot access it, engineers must drop what they're doing and troubleshoot the application, and the business as a whole suffers. The service mesh load balancer helps to route traffic to healthy instances (services), avoiding unhealthy instances and ultimately providing more application reliability.
Service mesh observability
You need easily-visible metrics to confirm that your containerized application is performing as expected. Understanding the success rate of the running app, the latency of user requests, and the overall traffic volume is key to understanding how well your application is currently performing and how it will perform later on. In short, if it doesn't perform well, you'll understand why.
As we've seen, service meshes provide powerful features. In the next section, we'll discuss why Linkerd specifically is a great option.
Why Linkerd Specifically?
In the previous section, we talked about why you might want to use a service mesh. If you talk to engineers, they usually recommend adopting a service mesh at the end of your Day Two operations and that you need a compelling reason to do so. This is because service meshes have a reputation for complexity - especially in the eyes of engineers new to Kubernetes and the service mesh concept - that drives many engineers to try to avoid them for as long as possible.
Linkerd, though, has a primary goal of minimizing this operational complexity in order to make it feasible to take advantage of a service mesh right from the start of Day One ops. Let’s take a look at how.
Deploying the Linkerd service mesh
In this section, we'll:
1. Deploy an application
2. Deploy Linkerd
3. View the application using Linkerd's visualization tools
To follow along, have a Kubernetes cluster ready, e.g., Minikube or Kind, or a production-ready cluster.
Installing the application
First, we'll install the application. We don't want this to be a simple "install this Nginx pod" demo, so let's use a popular microservice-based demo application. The Sock Shop app is used in many demos and is ideal for showcasing how a service mesh like Linkerd works.
First, clone the repo from GitHub.
git clone https://github.com/microservices-demo/microservices-demoNext, change your directory in the microservices-demo directory.
cd microservices-demoChange directories again into Kubernetes.
cd deploy/kubernetesCreate a Kubernetes Namespace for to deploy the Sock Shop app.
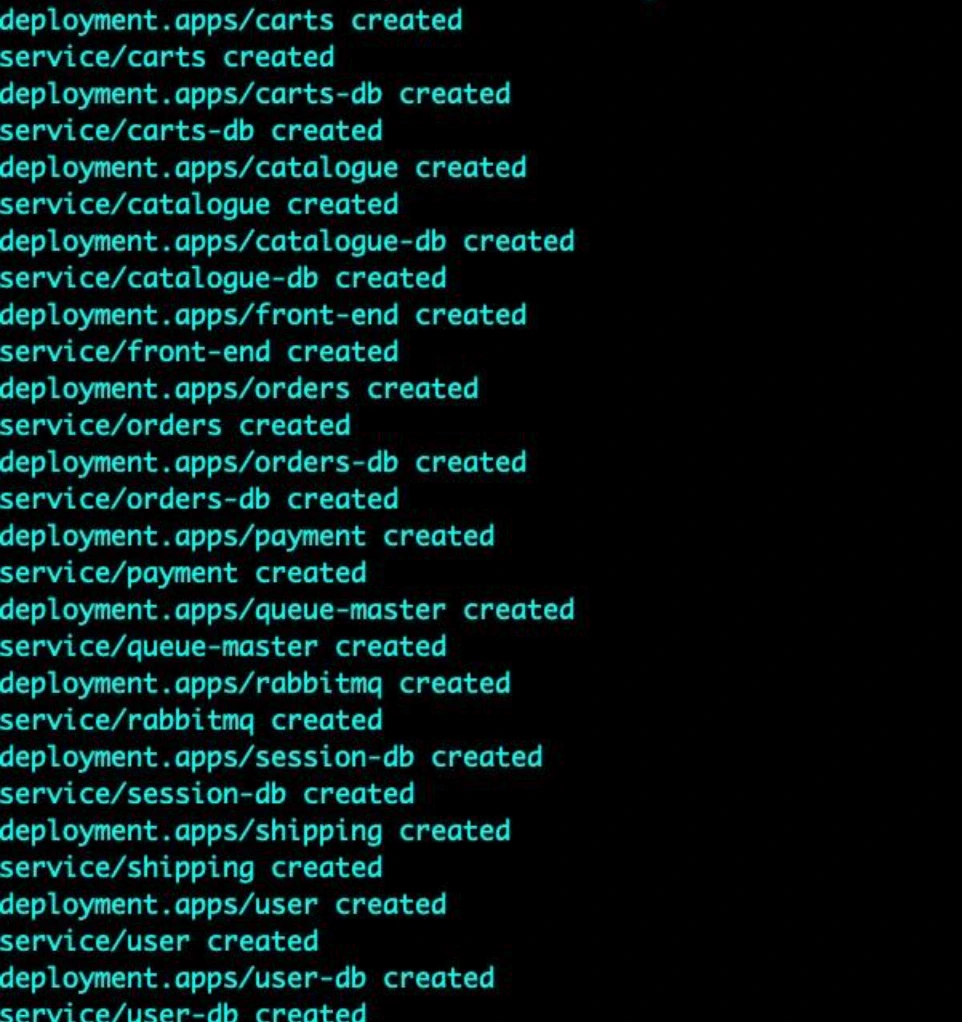
kubectl create namespace sock-shopDeploy the app.
kubectl apply -f complete-demo.yamlYou should see an output on the terminal similar to the screenshot below.
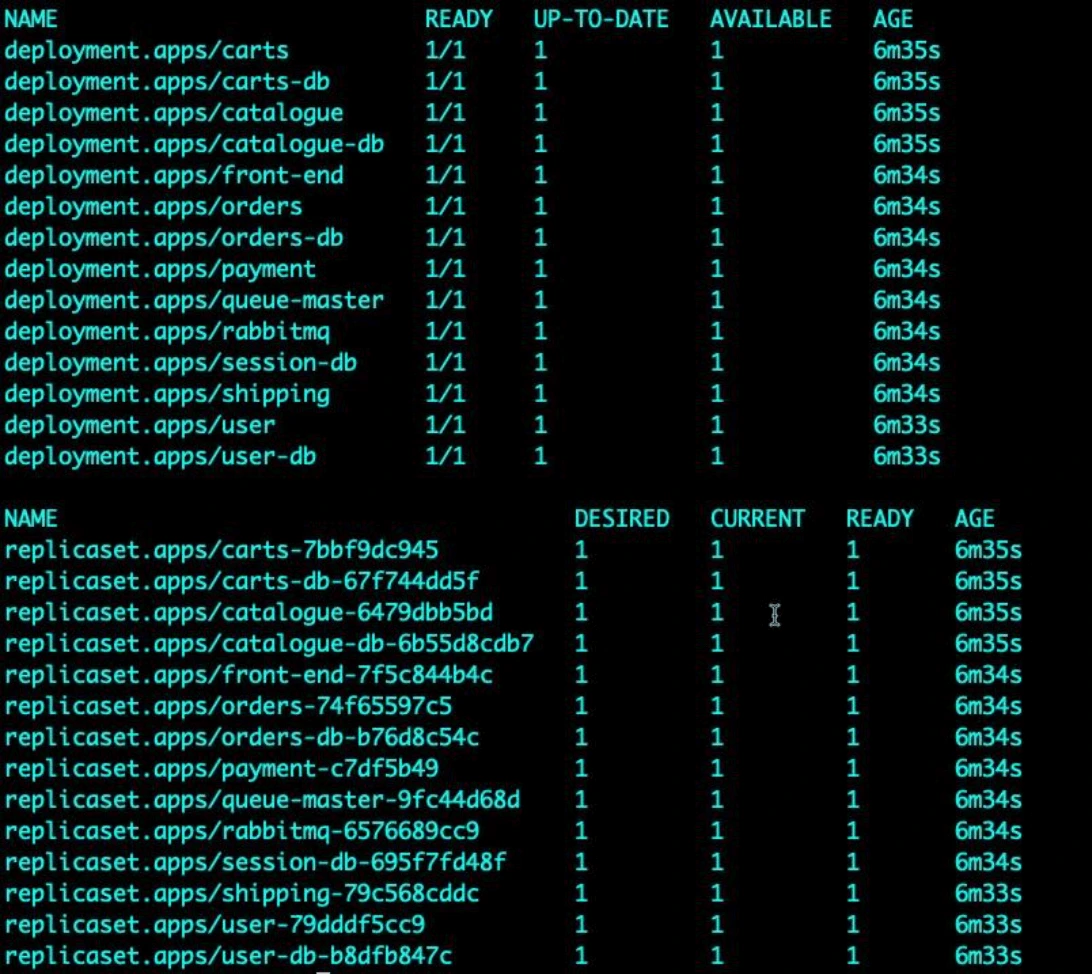
Wait a few minutes and run the following command to verify that all Kubernetes Sock Shop resources were created successfully.
kubectl get all -n sock-shop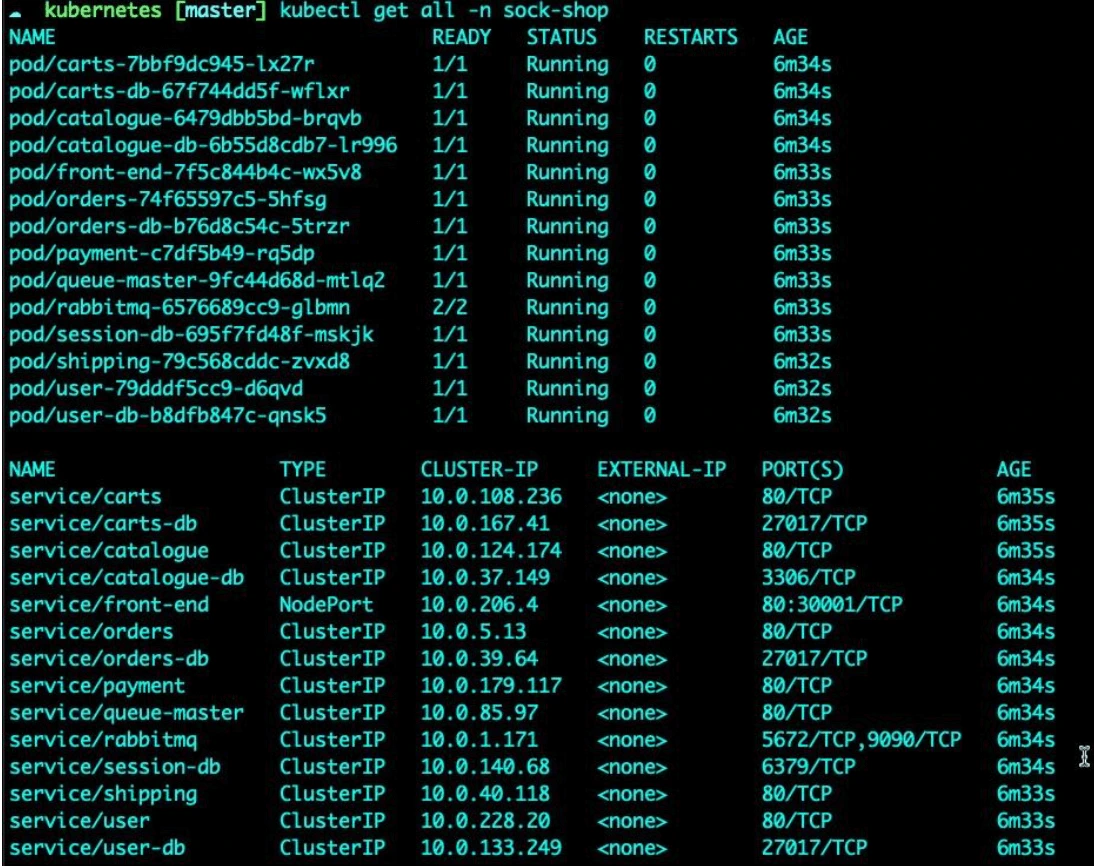
CLI Installation
Next up, install the Linkerd CLI. It will allow you to do things like check that your Kubernetes cluster is ready for Linkerd and deploy the dashboard (which you’ll see later).
Run the following to install the Linkerd CLI.
curl --proto '=https' --tlsv1.2 -sSfL https://run.linkerd.io/install | shAfter the installation, run the following command to confirm that it’s installed.
linkerd versionLinkerd Installation
First, you’ll need to install Linkerd. There are two methods:
- The CLI
- Helm
We’ll demonstrate using Helm, since it’s easier to version and upgrade your Linkerd deployment using Helm, making it somewhat better suited to production use.
First, confirm that the Kubernetes cluster is ready to run Linkerd.
linkerd check --pre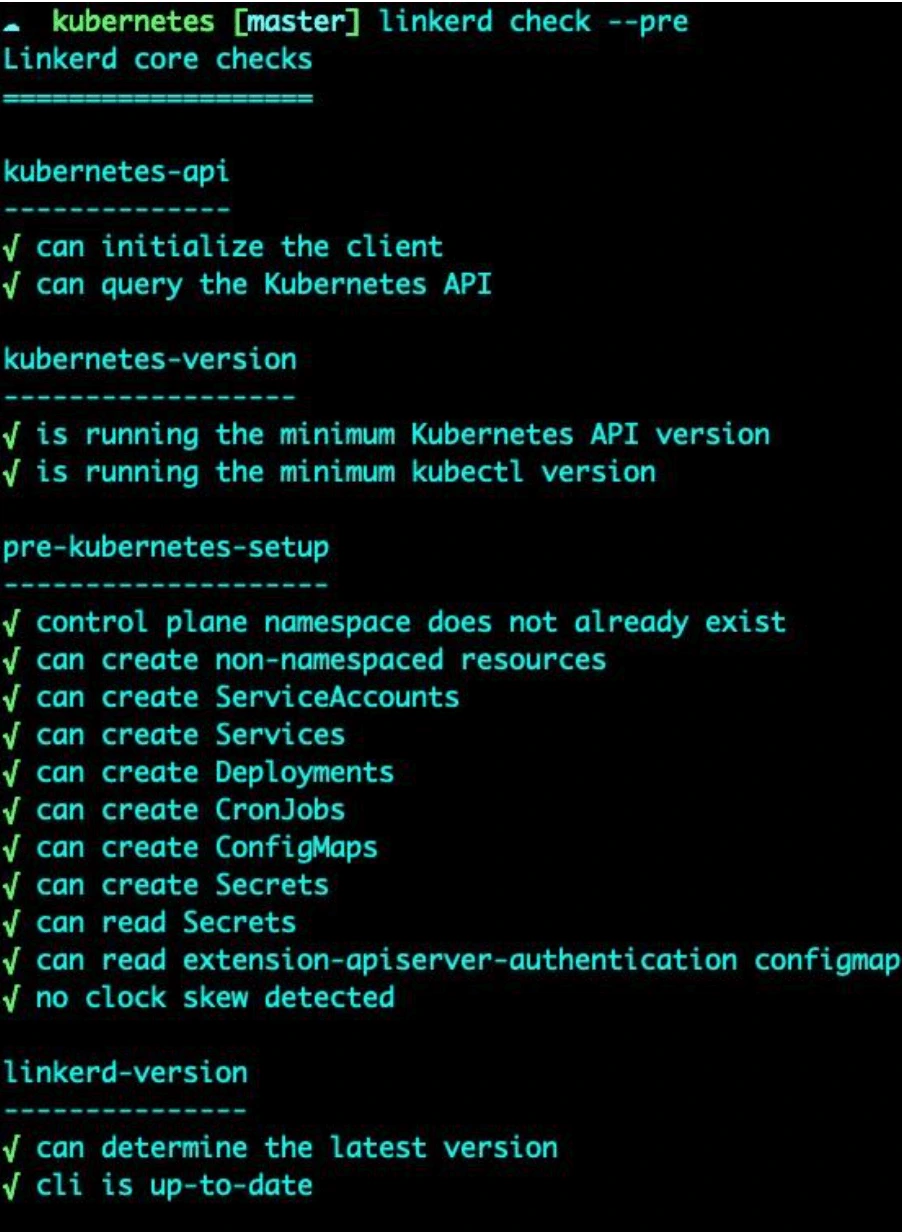
Next, add the Linkerd Helm chart.
helm repo add linkerd https://helm.linkerd.io/stableInstall the Linkerd Custom Resource Definitions (CRD).
helm install linkerd-crds linkerd/linkerd-crds \
-n linkerd --create-namespaceTo install the Linkerd Control Plane with Helm, you have two options:
1. High availability
2. Single node
For the HA installation, run the following Helm chart.
helm install linkerd-control-plane \
--set-file identityTrustAnchorsPEM=ca.crt \
--set-file identity.issuer.tls.crtPEM=issuer.crt \
--set-file identity.issuer.tls.keyPEM=issuer.key \
-f linkerd-control-plane/values-ha.yaml \
linkerd/linkerd-control-planeIf you’d prefer not to use the HA install (e.g., it's for a demo environment), you can use the following Helm chart:
-n linkerd \
--set-file identityTrustAnchorsPEM=ca.crt \
--set-file identity.issuer.tls.crtPEM=issuer.crt \
--set-file identity.issuer.tls.keyPEM=issuer.key \
linkerd/linkerd-control-planeTo confirm that Linkerd is installed, run the following to check the Kubernetes resources.
kubectl get all -n linkerdYou should see an output similar to the screenshot below.

Once deployed, you’ll need a way to get the Linkerd sidecar into the Sock Shop Namespace. The easiest way in this instance is to inject the sidecar into every containerized deployment via the inject command.
kubectl get deploy -o yaml -n sock-shop | linkerd inject - | kubectl apply -f -You’ll need to restart your Sock Shop Pods after this:
kubectl rollout restart -n sock-shop deploymentsView the app with Linkerd
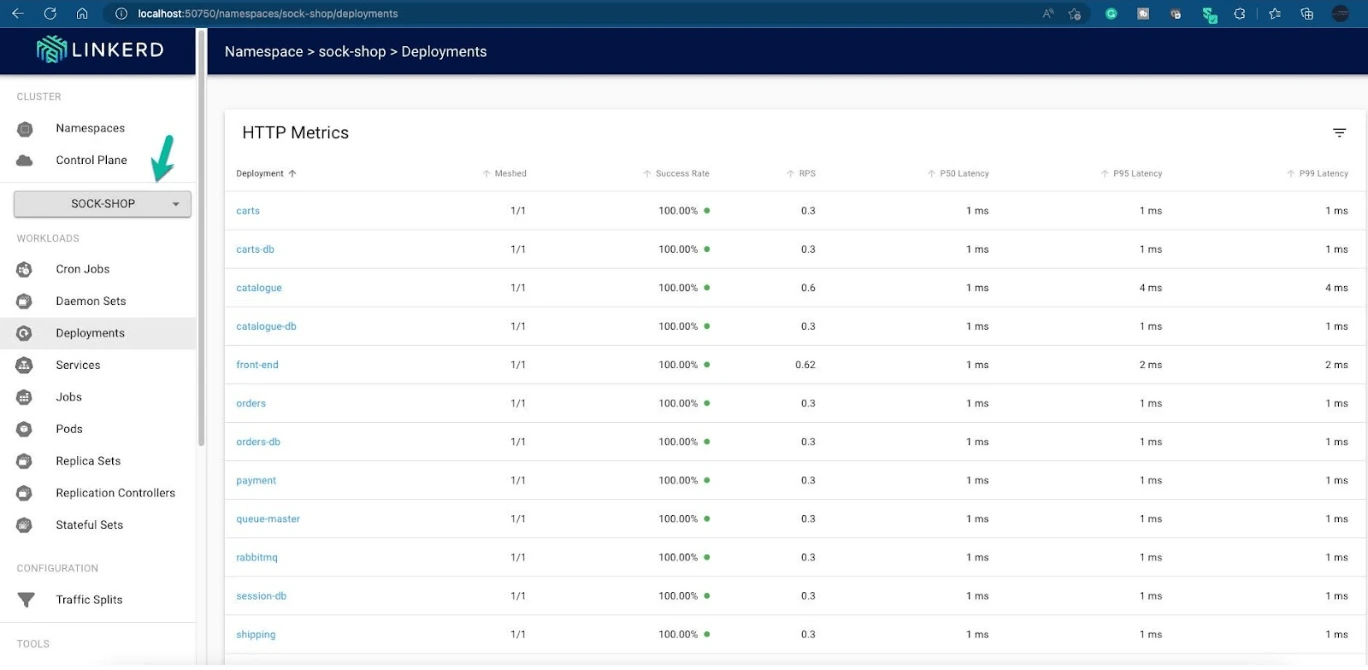
The final step is to view the microservice that you deployed in the application installation section in the Linkerd UI. First, install Viz.
Next, run Viz locally.
linkerd viz dashboard &The Viz dashboard will automatically open up for you.
Change the Namespace to the Sock Shop Namespace and you’ll now see that the containerized applications running in the Sock Shop Namespace are secured with Linkerd.ç
If you followed along, you hopefully realized how easy it is to install Linkerd. There is no reason to miss out on the security, reliability, and observability features a service mesh provides, even if you're new to Kubernetes. Linkerd's zero-config approach makes adopting a service mesh really easy. And don't forget to join the Linkerd Slack. Community member and maintainers will be happy to answer any questions.


